15 Chapter 15: Translation
Lisa Limeri; Joshua Reid; and rocksher
Learning Objectives
By the end of this section, you will be able to do the following:
-
Explain how the genetic code relates transcription to translation and why it is considered redundant.
-
On diagrams of translation initiation, translation elongation, and translation termination, label the small and large ribosomal subunits, mRNA, tRNA, rRNA, reading frame, start codon, stop codon, release factor, and tRNA binding sites (E, A, and P). Circle and label the locations where codon- anticodon recognition and peptide bond formation occur.
-
Use a copy of the genetic code to predict the sequence of the amino acids produced from a given mRNA or double-stranded DNA fragment. Identify the start and stop codon.

Introduction
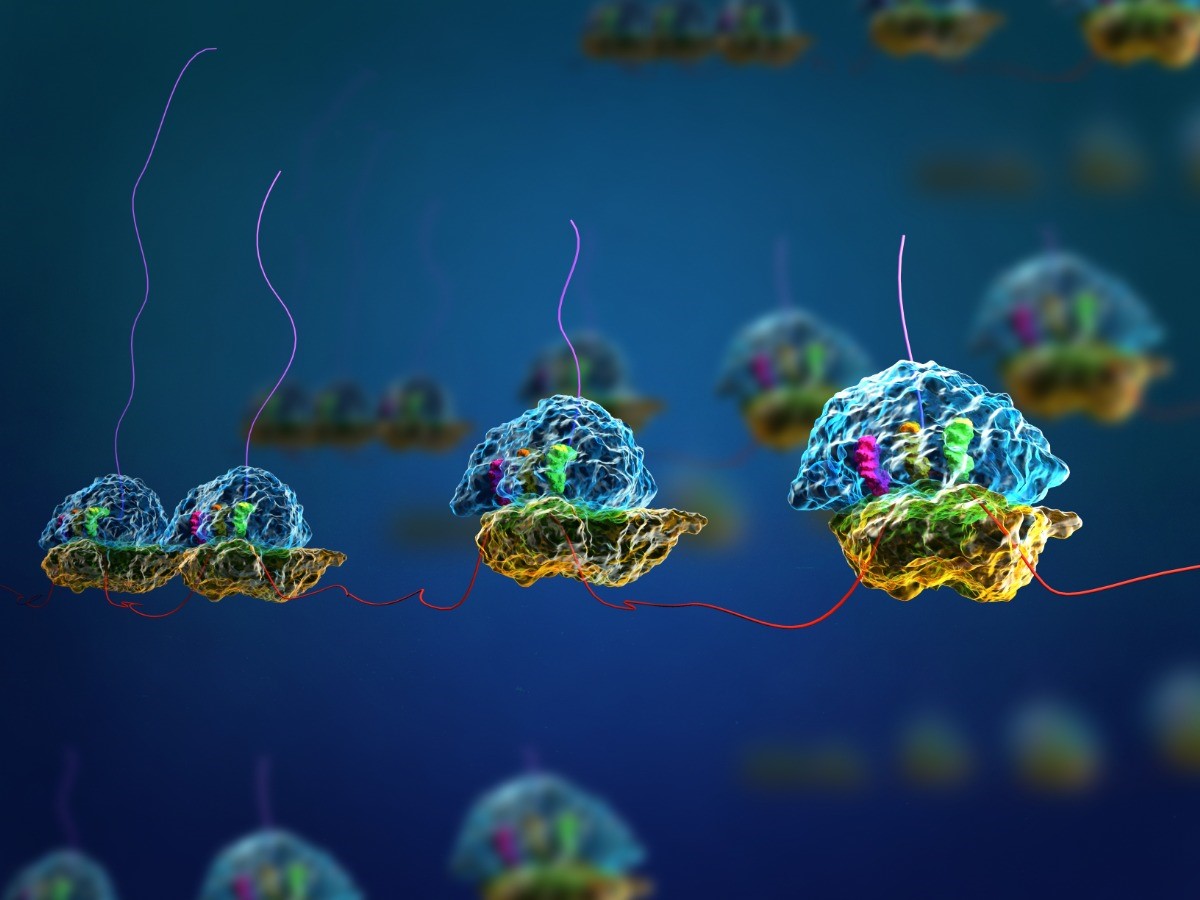
In the last chapter we learned how mRNA is produced from DNA through the process of transcription. Transcription is the first step of the Central Dogma. The final step of the central dogma is creating proteins based on the instructions carried in the mRNA in the process called translation (Fig 17.1). In this chapter, we will dive into the details of translation.
The synthesis of proteins consumes more of a cell’s energy than any other metabolic process. In turn, proteins account for more mass than any other component of living organisms (with the exception of water), and proteins perform virtually every function of a cell.
The Genetic Code
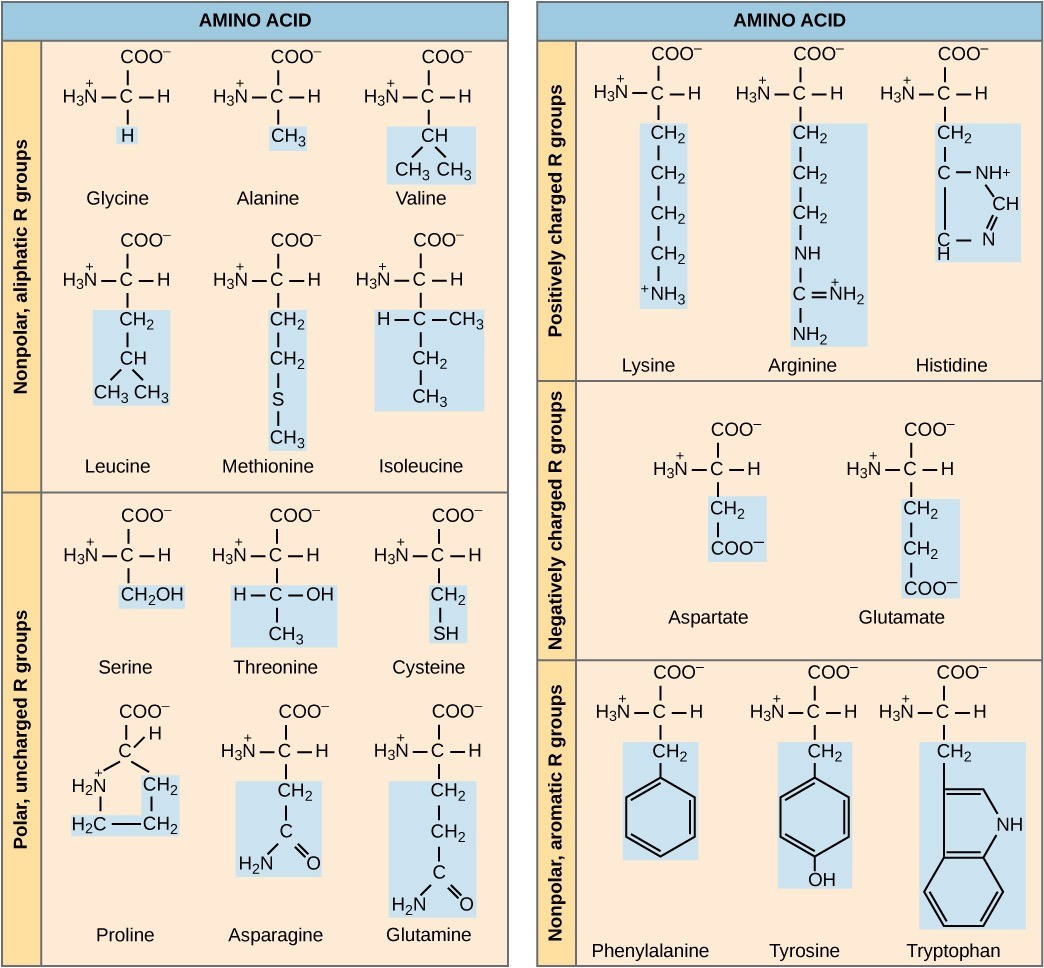
Transcription generates messenger RNA (mRNA), a mobile molecular copy of one or more genes with an alphabet of A, C, G, and U. Translation of the mRNA template on ribosomes converts nucleotide-based genetic information into a protein product. That is the central dogma of DNA-protein synthesis. Protein sequences consist of 20 commonly-occurring amino acids; therefore, it can be said that the protein alphabet consists of 20 “letters” (Figure 17.2). Different amino acids have different chemistries (such as acidic versus basic, or polar and non-polar) and different structural constraints. Variation in amino acid sequence is responsible for the enormous variation in protein structure and function.
Given the different numbers of “letters” in the “alphabets” of mRNA (only 4) and proteins (20), scientists theorized that single amino acids must be represented by combinations of nucleotides. Nucleotide doublets would not be sufficient to specify every amino acid because there are only 16 possible two-nucleotide combinations (42=16). Thus, the code cannot be a 2-nucleotide sequence, because there are not enough unique sequences for each amino acid to have a unique sequence. However, there are 64 possible nucleotide triplets (43=64), which is far more than the number of amino acids. This is why each amino acid is coded by a three-nucleotide sequence called the codon. This “code” linking triplets of nucleotides to amino acids is called the genetic code.
The genetic code is “degenerate,” meaning that a given amino acid could be encoded by more than one nucleotide triplet. Scientists predicted these principles based on the above logic and this was later confirmed experimentally: Francis Crick and Sydney Brenner used the chemical mutagen proflavin to insert one, two, or three nucleotides into the gene of a virus. When one or two nucleotides were inserted, the normal proteins were not produced. When three nucleotides were inserted, the protein was synthesized and functional. This demonstrated that the amino acids must be specified by groups of three nucleotides, which we call codons.
Scientists painstakingly solved the genetic code by translating synthetic mRNAs in vitro and sequencing the proteins they specified (Figure 17.3).
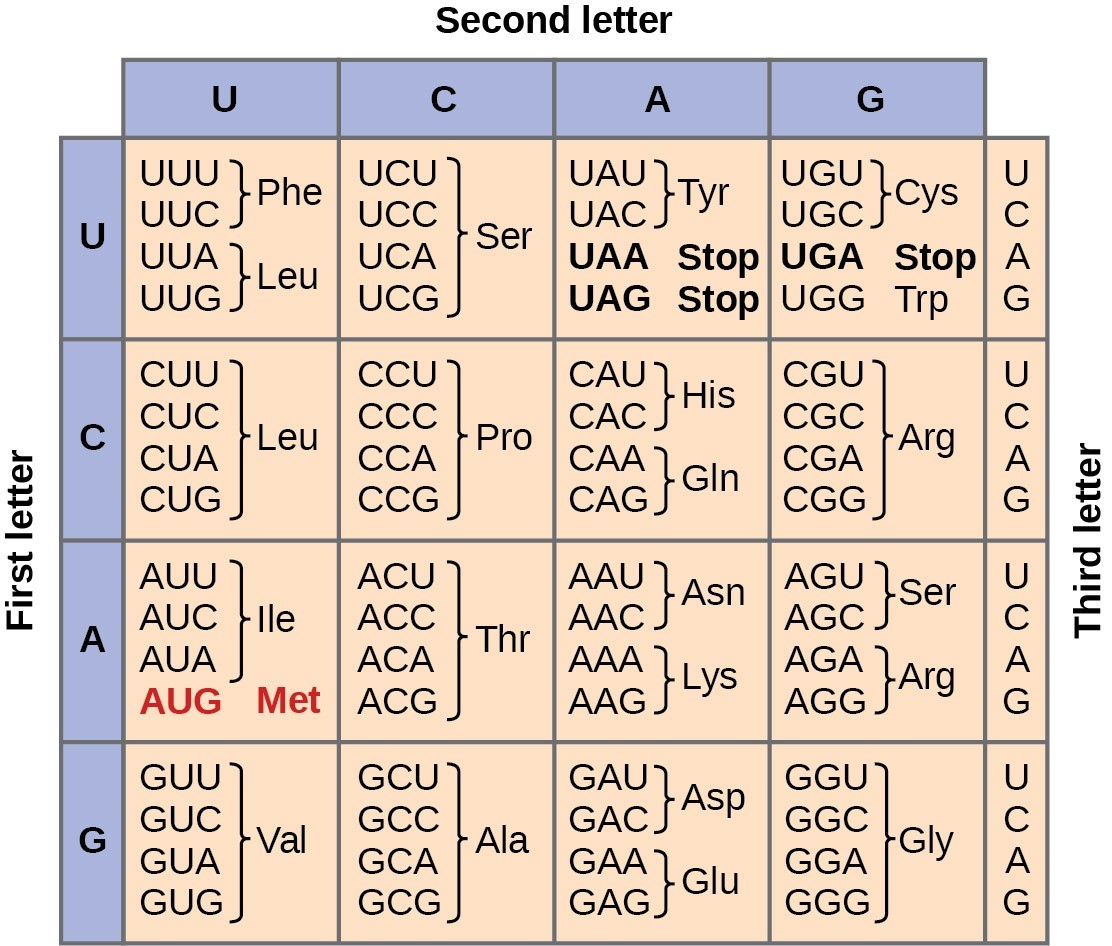
In addition to codons that instruct the addition of a specific amino acid to a polypeptide chain, three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery. These triplets are called stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5’ end of the mRNA. Following the start codon, the mRNA is read in groups of three until a stop codon is encountered.
The arrangement of the genetic code table reveals the structure of the code. There are sixteen “blocks” of codons, each specified by the first and second nucleotides of the codons within the block, e.g., the “AC*” block that corresponds to the amino acid threonine (Thr). Some blocks are divided into a pyrimidine half, in which the codon ends with U or C, and a purine half, in which the codon ends with A or G. Some amino acids get a whole block of four codons, like alanine (Ala), threonine (Thr) and proline (Pro). Some get the pyrimidine half of their block, like histidine (His) and asparagine (Asn). Others get the purine half of their block, like glutamate (Glu) and lysine (Lys). Note that some amino acids get a block and a half-block for a total of six codons.
The specification of a single amino acid by multiple similar codons is called “degeneracy.” Degeneracy is believed to be a cellular mechanism to reduce the negative impact of random mutations. Codons that specify the same amino acid typically only differ by one nucleotide. In addition, amino acids with chemically similar side chains are encoded by similar codons. For example, aspartate (Asp) and glutamate (Glu), which occupy the GA* block, are both negatively charged. This nuance of the genetic code ensures that a single-nucleotide substitution mutation might specify the same amino acid but have no effect or specify a similar amino acid, preventing the protein from being rendered completely nonfunctional.
The genetic code is nearly universal. With a few minor exceptions, virtually all species use the same genetic code for protein synthesis. Conservation of codons means that a purified mRNA encoding the globin protein in horses could be transferred to a tulip cell, and the tulip would synthesize horse globin. That there is only one genetic code is powerful evidence that all of life on Earth shares a common origin, especially considering that there are about 1084 possible combinations of 20 amino acids and 64 triplet codons.
Reading Question #1
What is the term used to describe the property of the genetic code where a single amino acid can be specified by multiple similar codons?
A. Codon diversity
B. Codon universality
C. Degeneracy
D. Genetic specification
Reading Question #2
What is the function of the start codon AUG in the genetic code?
A. It specifies the amino acid methionine.
B. It terminates protein synthesis and releases polypeptides.
C. It sets the reading frame for translation at the 3’ end of the mRNA.
D. It initiates translation and sets the reading frame at the 5’ end of the mRNA.

Ribosomes and Protein Synthesis
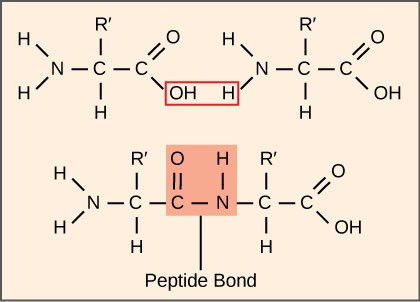
The process of translation, or protein synthesis, involves the decoding of an mRNA message into a polypeptide product. Amino acids are covalently strung together by interlinking peptide bonds in lengths ranging from approximately 50 to more than 1000 amino acid residues. Polypeptides are formed when the amino group of one amino acid forms an amide (i.e., peptide) bond with the carboxyl group of another amino acid (Figure 17.4). This reaction is catalyzed by ribosomes.
The Protein Synthesis Machinery
In addition to the mRNA template, many molecules and macromolecules contribute to the process of translation. The composition of each component may vary across species (for example, ribosomes may consist of different numbers of rRNAs and polypeptides depending on the organism). However, the general structures and functions of the protein synthesis machinery are comparable from bacteria to human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors.
Ribosomes
Even before an mRNA is translated, a cell must invest energy to build each of its ribosomes. In E. coli, there are between 10,000 and 70,000 ribosomes present in each cell at any given time. A ribosome is a complex macromolecule composed of structural and catalytic rRNAs, and many distinct polypeptides. In eukaryotes, the nucleolus is completely specialized for the synthesis and assembly of rRNAs.
Ribosomes exist in the cytoplasm of prokaryotes and in the cytoplasm and rough endoplasmic reticulum of eukaryotes. Mitochondria and chloroplasts also have their own ribosomes in the matrix and stroma, which look more similar to prokaryotic ribosomes (and have similar drug sensitivities) than the ribosomes just outside their outer membranes in the cytoplasm. Ribosomes dissociate into large and small subunits when they are not synthesizing proteins and reassociate during the initiation of translation. In E. coli, the small subunit is described as 30S, and the large subunit is 50S, for a total of 70S (Svedberg units are not additive). Mammalian ribosomes have a small 40S subunit and a large 60S subunit, for a total of 80S. The small subunit is responsible for binding the mRNA template, whereas the large subunit sequentially binds tRNAs. Each mRNA molecule is simultaneously translated by many ribosomes, all synthesizing protein in the same direction: reading the mRNA from 5′ to 3′ and synthesizing the polypeptide from the N terminus to the C terminus. The complete mRNA/poly-ribosome structure is called a polysome (Fig 17.1).
Transfer RNAs (tRNAs)
The Transfer RNAs (tRNAs) are structural RNA molecules that were transcribed from genes by RNA polymerase III. Depending on the species, 40 to 60 types of tRNAs exist in the cytoplasm. Transfer RNAs serve as adaptor molecules. Each tRNA carries a specific amino acid and recognizes one or more of the mRNA codons that define the order of amino acids in a protein. Aminoacyl-tRNAs bind to the ribosome and add the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins.
Of the 64 possible mRNA codons—or triplet combinations of A, U, G, and C—three specify the termination of protein synthesis and 61 specify the addition of amino acids to the polypeptide chain. Of these 61, one codon (AUG) also encodes the initiation of translation. Each tRNA anticodon can base pair with one or more of the mRNA codons for its amino acid. For instance, if the sequence CUA occurred on an mRNA template in the proper reading frame, it would bind a leucine tRNA expressing the complementary sequence, GAU. The ability of some tRNAs to match more than one codon is what gives the genetic code its blocky structure.
As the adaptor molecules of translation, it is surprising that tRNAs can fit so much specificity into such a small package. Consider that tRNAs need to interact with three factors: 1) they must be recognized by the correct aminoacyl synthetase (see below); 2) they must be recognized by ribosomes; and 3) they must bind to the correct sequence in mRNA.
Aminoacyl tRNA Synthetases
The process of pre-tRNA synthesis by RNA polymerase III only creates the RNA portion of the adaptor molecule. The corresponding amino acid must be added later, once the tRNA is processed and exported to the cytoplasm. Through the process of tRNA “charging,” each tRNA molecule is linked to its correct amino acid by one of a group of enzymes called aminoacyl tRNA synthetases. At least one type of aminoacyl tRNA synthetase exists for each of the 20 amino acids; the exact number of aminoacyl tRNA synthetases varies by species. The term “charging” is appropriate, since the high-energy bond that attaches an amino acid to its tRNA is later used to drive the formation of the peptide bond. Each tRNA is named for its amino acid.
The Mechanism of Protein Synthesis
As with mRNA synthesis, protein synthesis can be divided into three phases: initiation, elongation, and termination. The process of translation is similar in prokaryotes and eukaryotes. Here we’ll explore how translation occurs in E. coli, a representative prokaryote, and specify any differences between prokaryotic and eukaryotic translation.
Initiation of Translation
Protein synthesis begins with the formation of an initiation complex. In E. coli, this complex involves the small 30S ribosome, the mRNA template, three initiation factors (IFs; IF-1, IF-2, and IF-3), and a special initiator tRNA, called tRNAMetf.
In E. coli mRNA, a sequence upstream of the first AUG codon, called the Shine-Dalgarno sequence (AGGAGG), interacts with the rRNA molecules that compose the ribosome. This interaction anchors the 30S ribosomal subunit at the correct location on the mRNA template. Guanosine triphosphate (GTP), which is a nucleotide triphosphate similar to ATP, acts as an energy source during translation—both at the start of elongation and during the ribosome’s translocation.
The initiator tRNA then interacts with the start codon, AUG. This tRNA carries the amino acid methionine, which is formylated (i.e., has a formyl carboxyl group attached), and is thus called fMet. The formylation creates a “faux” peptide bond between the formyl carboxyl group and the amino group of the methionine. The fMet begins every polypeptide chain synthesized by E. coli, but it is usually removed after translation is complete. When an in-frame AUG is encountered during translation elongation, a non-formylated methionine is inserted by a regular Met-tRNAMet. After the formation of the initiation complex, the 30S ribosomal subunit is joined by the 50S subunit to form the translation complex.
In eukaryotes, a similar initiation complex forms, comprising mRNA, the 40S small ribosomal subunit, eukaryotic IFs, and nucleoside triphosphates (GTP and ATP). The methionine on the charged initiator tRNA, called Met-tRNAi, is not formylated. However, Met-tRNAi is distinct from other Met-tRNAs in that it can bind IFs.
Instead of the Shine-Dalgarno sequence, the eukaryotic initiation complex recognizes the 7-methylguanosine cap at the 5′ end of the mRNA. A cap-binding protein (CBP) and several other IFs assist the movement of the ribosome to the 5′ cap. Once at the cap, the initiation complex tracks along the mRNA in the 5′ to 3′ direction, searching for the AUG start codon. Once the AUG is identified, the other proteins and CBP dissociate, and the 60S subunit binds to the complex of Met-tRNAi, mRNA, and the 40S subunit. This step completes the initiation of translation in eukaryotes.
Translation Elongation
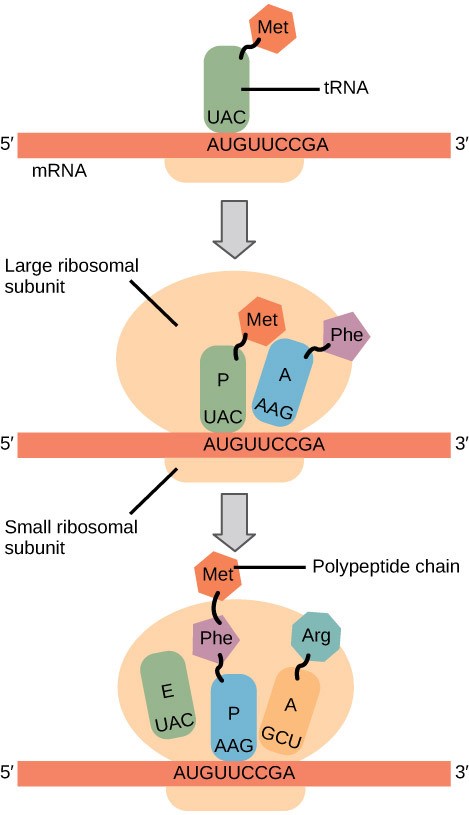
In prokaryotes and eukaryotes, the basics of elongation are the same. When the translation complex is formed, the tRNA binding region of the ribosome consists of three compartments (Fig 17.5). The A (aminoacyl) site binds incoming charged aminoacyl tRNAs. The P (peptidyl) site binds charged tRNAs carrying amino acids that have formed peptide bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E (exit) site releases dissociated tRNAs so that they can be recharged with free amino acids. During elongation, the mRNA template provides tRNA binding specificity. As the ribosome moves along the mRNA, each mRNA codon comes into register, and specific binding with the corresponding charged tRNA anticodon is ensured.

Elongation proceeds with charged tRNAs sequentially entering and leaving the ribosome as each new amino acid is added to the polypeptide chain. Movement of a tRNA from A to P to E site is induced by conformational changes that advance the ribosome by three bases in the 3′ direction. The energy for each step along the ribosome is provided by elongation factors that hydrolyze GTP. GTP energy is required both for the binding of a new aminoacyl-tRNA to the A site and for its translocation to the P site after formation of the peptide bond. Peptide bonds form between the amino group of the amino acid attached to the A-site tRNA and the carboxyl group of the amino acid attached to the P-site tRNA. The formation of each peptide bond is catalyzed by peptidyl transferase, an RNA-based enzyme that is integrated into the 50S ribosomal subunit. The energy for each peptide bond formation is derived from the high-energy bond linking each amino acid to its tRNA. After peptide bond formation, the A-site tRNA that now holds the growing peptide chain moves to the P site, and the P-site tRNA that is now empty moves to the E site and is expelled from the ribosome (Figure 17.6). Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200-amino acid protein can be translated in just 10 seconds.
Many antibiotics inhibit bacterial protein synthesis. For example, tetracycline blocks the A site on the bacterial ribosome, and chloramphenicol blocks peptidyl transfer.
Termination of Translation
Termination of translation occurs when a stop codon (UAA, UAG, or UGA) is encountered. Upon aligning with the A site, these stop codons are recognized by protein release factors that resemble tRNAs. The releasing factors in both prokaryotes and eukaryotes instruct peptidyl transferase to add a water molecule to the carboxyl end of the P-site amino acid. This reaction forces the P-site amino acid to detach from its tRNA, and the newly made protein is released. The small and large ribosomal subunits dissociate from the mRNA and from each other; they are recruited almost immediately into another translation initiation complex. After many ribosomes have completed translation, the mRNA is degraded so the nucleotides can be reused in another transcription reaction.
Reading Question #3
Which molecule catalyzes the formation of peptide bonds during translation?
A. Ribosomes
B. mRNA
C. tRNA
D. Aminoacyl tRNA synthetases
Reading Question #4
What is the function of protein release factors during translation termination?
A. They catalyze the formation of peptide bonds.
B. They bind to the A site and add amino acids to the growing polypeptide chain.
C. They recognize stop codons and release the completed protein from the ribosome.
D. They hydrolyze GTP to provide energy for elongation.
Mutations
DNA replication is a highly accurate process, but mistakes can occasionally occur, such as a DNA polymerase inserting a wrong base. Uncorrected mistakes may sometimes lead to serious consequences, such as cancer. Repair mechanisms correct the mistakes. In rare cases, mistakes are not corrected, leading to mutations. Errors during DNA replication are not the only reason why mutations arise in DNA. Mutations, variations in the nucleotide sequence of a genome, can also occur because of damage to DNA.
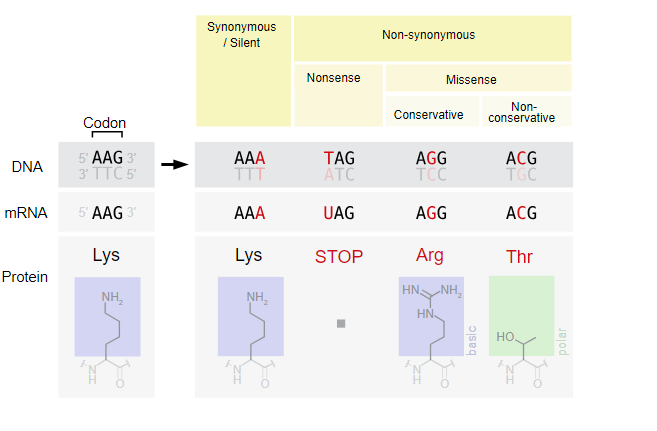
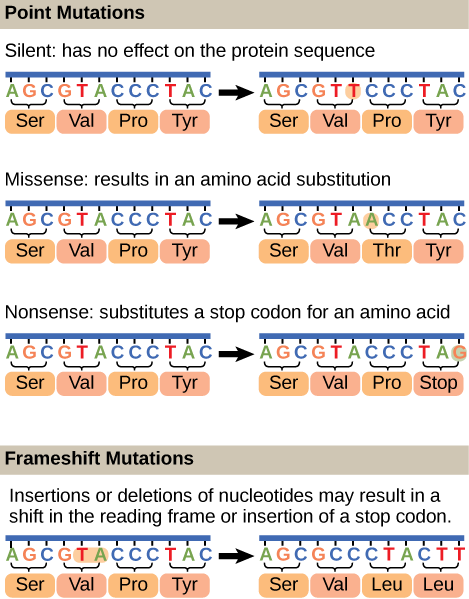
Mutations may have a wide range of effects. Point mutations are those mutations that affect a single base pair (Figure 17.7). The most common nucleotide mutations are substitutions, in which one base is replaced by another. Some point mutations are not detectable in the final product; these are known as silent mutations. Silent mutations are usually due to a substitution in the third base of a codon, which often represents the same amino acid as the original codon. Point mutations that generate a stop codon are called nonsense mutation and terminate a protein early. This results in the production of a protein shorter than the original. Other point mutations, called missense mutations, results in the replacement of one amino acid by another, which may alter the function of the protein. In Figure 17.7, the positively charged amino acid lysine is changed to threonine, a polar uncharged amino acid. The alteration is the character of the amino acid in the primary sequence may have downstream effects on the tertiary or quaternary structure of the protein, thus impacting the protein function.
Mutations can also be the result of the addition of a base, known as an insertion, or the removal of a base, also known as deletion. If an insertion or deletion results in the alteration of the translational reading frame (a frameshift mutation), the resultant protein is usually nonfunctional. These mutation types are shown in Figure 17.8 below.
Reading Question #5
Which type of mutation results in the replacement of one amino acid by another, potentially altering the function of the protein?
A. Silent mutation
B. Nonsense mutation
C. Missense mutation
D. Frameshift mutation
Research Connection: Harmful Mutations
There are two types of genetic mutations: synonymous (does not alter protein sequences) and nonsynonymous (alters protein sequences). Since the genetic code was solved, synonymous mutations were generally presumed to have a neutral or nearly-neutral effect on an organism. However, new research led by Dr. Jianzhi Zhang and Xukang Shen has shown that this belief is far from the truth. Their study focusing on yeasts discovered that approximately 75 percent of synonymous mutations were significantly harmful to the organism (Shen et al., 2022). These findings suggest that both synonymous and nonsynonymous mutations are important in causing disease. Future research should be conducted with other organisms to confirm their findings, but the authors note that “there is no particular reason why their results would be restricted to yeast” (University of Michigan, 2022).
Acknowledgements
Adapted from Clark, M.A., Douglas, M., and Choi, J. (2018). Biology 2e. OpenStax. Retrieved from https://openstax.org/books/biology-2e/pages/1-introduction

{kind=link}
{kind=link}