4 Chapter 4: DNA Structure and Function
Lisa Limeri; Joshua Reid; rocksher; and Shifath Bin Syed
Learning Objectives
By the end of this section, you will be able to do the following:
- Define complementary base pairing, and explain its connection to the observation that DNA strands are antiparallel.
- Use the pairing rules to 1) explain the observation that in DNA, %A =%T and %G = %C, 2) predict the sequence of a complementary strand of DNA when given one strand, and 3) calculate the percentage of each base in a DNA molecule when given the percentage of one base.
- Explain the contributions of Rosalind Franklin, Maurice Wilkins, James Watson, and Francis Crick in the discovery of the structure of DNA.
Introduction
In the last couple of chapters, we have explored different cell cycle phases. Last chapter, we learned about how chromosomes move and separate into new cells during mitosis. For this to be possible, DNA was first replicated during the S phase. Next, we will focus on DNA replication during the S phase. But, before we can begin understanding how DNA is replicated, we need first to learn a bit about the structure of DNA. The structure is tightly linked to function, so understanding how DNA does its job requires understanding what it looks like.
Molecules are made up of atoms bound together
To begin understanding the structure of DNA, we need to understand some basic chemistry principles first. Here we will review some relevant chemistry concepts that will aid our understanding of DNA’s structure and function.
Molecules are composed of atoms connected to each other via chemical bonds. For example, the familiar water molecule, H2O, consists of two hydrogen atoms and one oxygen atom. These bond together to form water, as Figure 5.1 illustrates. Atoms can form molecules by donating, accepting, or sharing electrons to fill their outer electron shells. When atoms donate or accept electrons, an ionic bond is created. When atoms share electrons, a covalent bond is the result. Today we will focus primarily on covalent bonds. We will revisit ionic bonds later in the semester when we talk about how proteins are formed and interact with each other. Covalent bonds are ubiquitous in organic chemistry. We commonly find covalent bonds in carbon-based organic molecules like DNA and proteins.
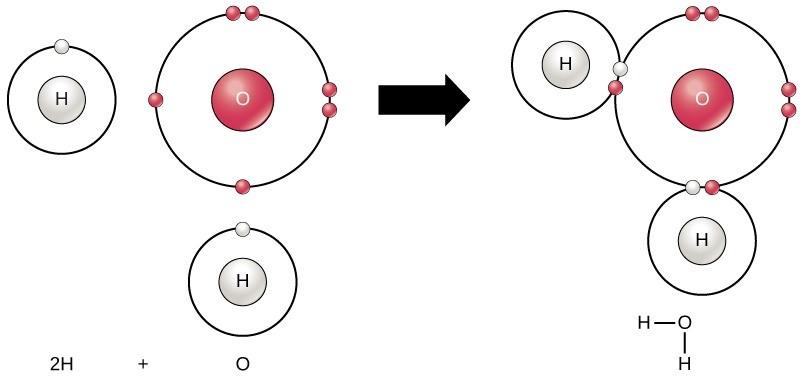
Covalent Bonds are Either Polar or Non-polar
There are two types of covalent bonds: polar and non-polar. In a polar covalent bond, atoms share the electrons unequally, meaning that the electrons are attracted more to one nucleus than the other. Electrons are negatively charged. So, because they are more closely associated with one atom than the other, a partially positive (δ+) or partially negative (δ–) charge develops (note that δ is the lowercase Greek letter delta and is the symbol for partial charges). This partial charge is an essential property of polar covalent bonds and accounts for many of their characteristics.
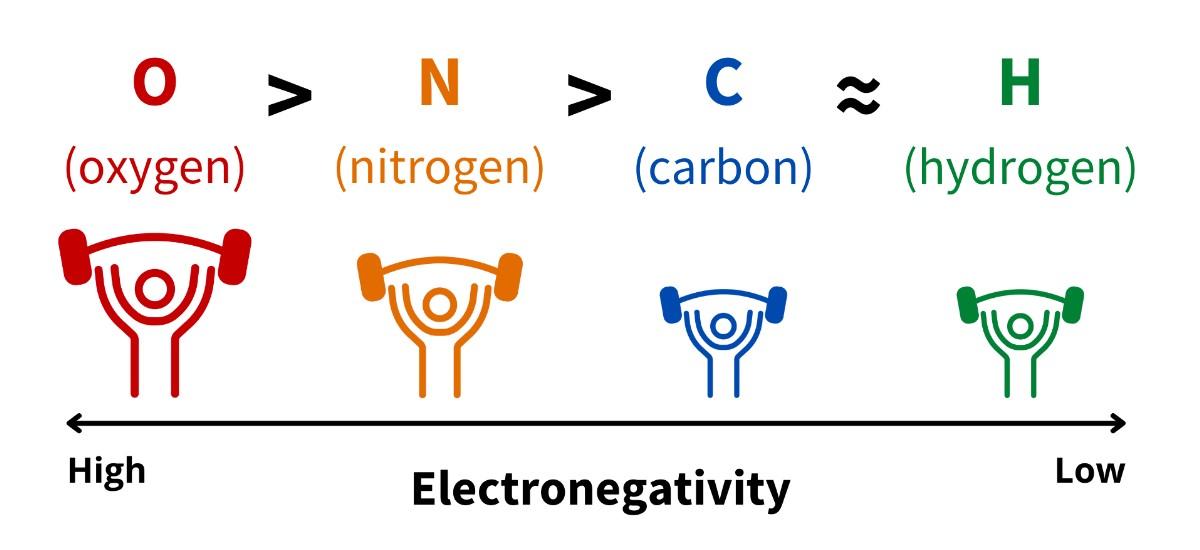
Unequal sharing of electrons occurs because elements differ in how strongly they attract electrons, a property called electronegativity. Each element has a unique electronegativity value (which can be found on the periodic table of elements). Elements with higher electronegativity values attract electrons more strongly than elements with lower electronegativities (Fig 4.2). For example, oxygen has a very high electronegativity value. It is the highest of the elements you will commonly encounter in biochemistry. In contrast, hydrogen has among the lowest electronegativities you will encounter in biochemistry.
The impact of differences in electronegativities is observed in a water molecule. When an oxygen atom is bound to two hydrogen atoms to create a water molecule, the shared electrons spend more time near the oxygen nucleus than the hydrogen atoms’ nuclei, giving the oxygen and hydrogen atoms slightly negative and positive charges, respectively (Figure 4.3).
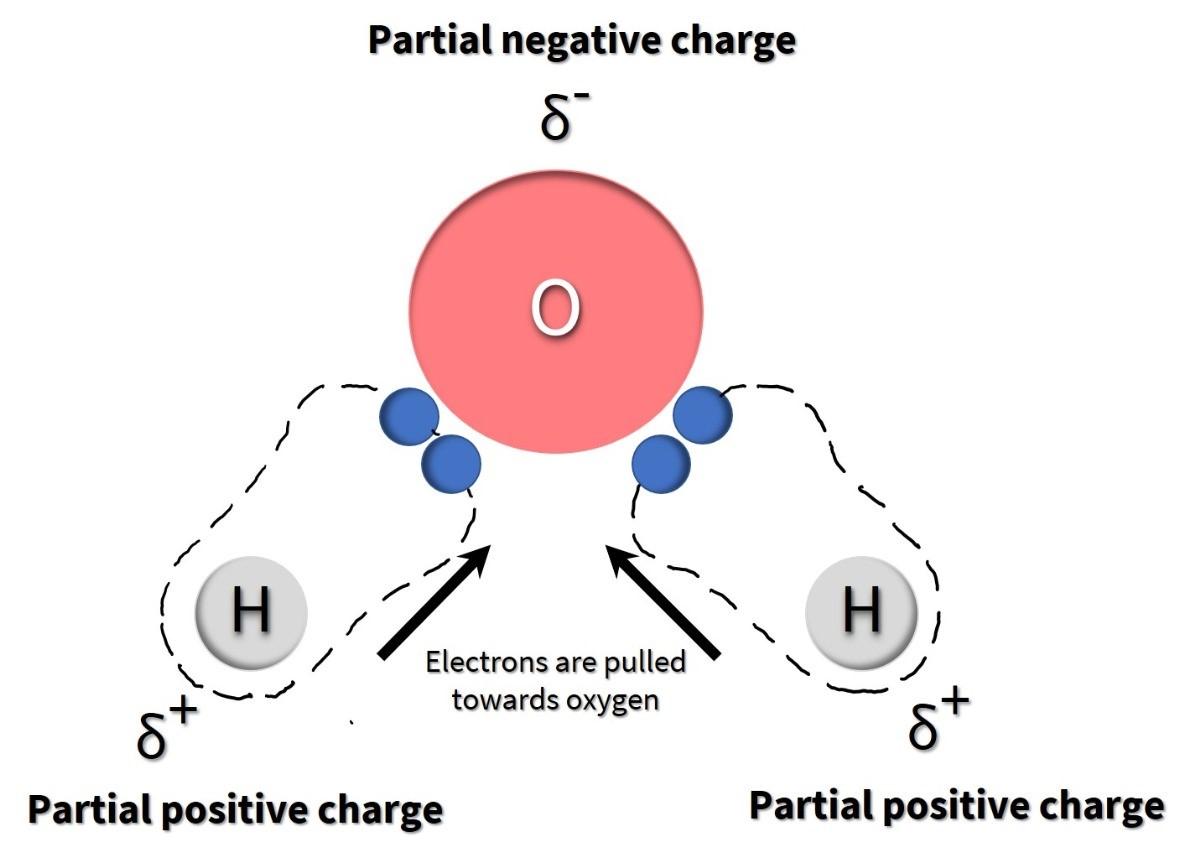
When a covalent bond forms between two atoms that have similar electronegativities, then they share electrons equally, creating a non-polar covalent bond. Any time an atom is bound to another atom of the same element (for example, molecular oxygen, O2), the bond will be non-polar because both atoms have the same electronegativity (electronegativity is a property of the element). Non-polar bonds will also arise when two atoms that have very similar electronegativity values are bound together, such as carbon and hydrogen (Fig 4.2).
Hydrogen Bonds are attractions between partial charges
We care about the polarity of covalent bonds because they create partial positive and partial negative charges that are attracted to each other. This attraction is called hydrogen bonding. It’s important to recognize that “hydrogen bonding” is a terrible name for this phenomenon. It does not describe all bonds that hydrogen is involved in. When hydrogen is covalently bonded to oxygen, it’s a polar covalent bond, NOT a hydrogen bond; when hydrogen is covalently bonded to carbon, is a non-polar covalent bond, NOT a hydrogen bond. Further, the word “bond” in the name is a misnomer. Hydrogen bonds are not bonds. They are weak attractions between atoms with partial positive and partial negative charges.
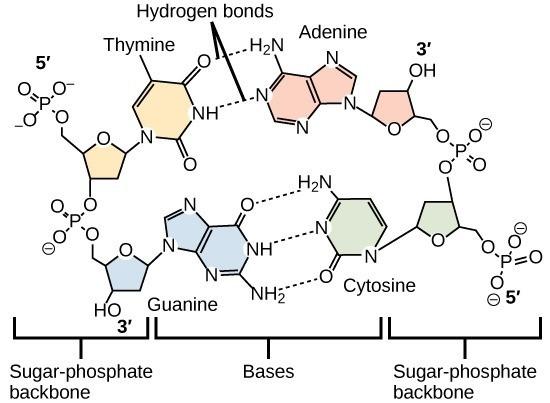
Hydrogen bonds are called so because they most commonly involve hydrogen as the atom with a partial positive charge. Because the hydrogen has a partial positive charge, it will be attracted to nearby partial negative charges (almost always on oxygens or nitrogens). Hydrogen bonding is critically important to understanding how organic molecules function and interact with each other. Although they are individually weak, they typically occur in very large numbers and, thus, together create very strong attractions. The importance of hydrogen bonds in nature is observed in a molecule of DNA. The hydrogen bonds between adjacent bases are the only force that keeps the two strands of DNA connected in double-stranded DNA (Fig 4.4).
Nucleotides are the Building Blocks of DNA
Now that we have chemistry basics down, we’re ready to dive into the building blocks for DNA – Nucleotides. A common theme you will see repeated is that biologically-important molecules (macromolecules) are made up of particular pieces that function like building blocks. The building blocks are called monomers, and when multiple monomers are bound together, they create a large molecule called a polymer. DNA is a polymer made up by bonding numerous nucleotides (the monomers).
Each nucleotide is made up of 3 components: a nitrogenous base, a pentose (five-carbon) sugar, and one or more phosphate groups (Fig 4.5).
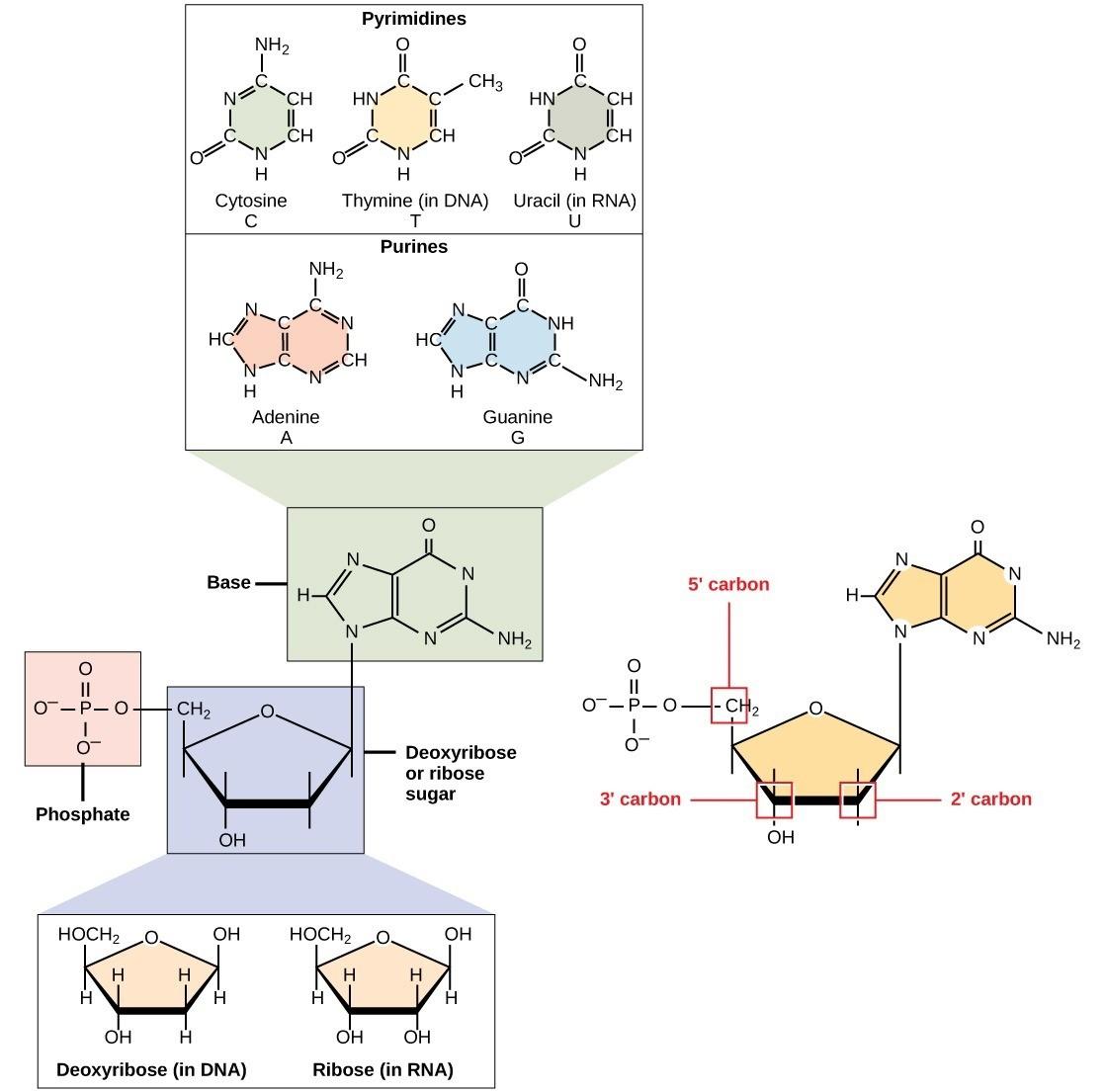
Nitrogenous bases, important components of nucleotides, are organic molecules and are so named because they contain carbon and nitrogen. They are bases because they contain an amino group that has the potential of binding an extra hydrogen, thus decreasing the hydrogen ion concentration in its environment, making it more basic. Each nucleotide in DNA contains one of four possible nitrogenous bases: adenine (A), guanine (G), cytosine (C), and thymine (T).
Adenine (A) and guanine (G) are classified as purines. The purine’s primary structure is two carbon-nitrogen rings. Cytosine (C), thymine (T), and uracil (U) are classified as pyrimidines, with a single carbon-nitrogen ring as their primary structure (Fig 4.5). Each of these basic carbon-nitrogen rings has different functional groups attached to it. DNA contains A, T, G, and C, whereas RNA contains A, U, G, and C.
The pentose sugar in DNA is deoxyribose, and in RNA, the sugar is ribose (Fig 4.5). The difference between the sugars is the presence of the hydroxyl group on the ribose’s 2′ carbon and hydrogen on the deoxyribose’s 2′ carbon. The carbon atoms of the sugar molecule are numbered 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”). The phosphate residue attaches to the hydroxyl group of the 5′ carbon of one sugar and the hydroxyl group of the 3′ carbon of the sugar of the next nucleotide, which forms a phosphodiester linkage. Phosphodiester linkages are formed by removing two phosphate groups from a free nucleotide. A DNA molecule may have thousands of such phosphodiester linkages.
Reading Check #1
Which components make up a nucleotide?
A. Nitrogenous base, pentose sugar, and phosphate group
B. Nitrogenous base, amino acid, and ribose sugar
C. Pentose sugar, phosphate group, and lipid molecule
D. Amino acid, nitrogenous base, and phosphate group
DNA Structure
In the 1950s, the findings of several scientists, including Francis Crick, James Watson, Rosalind Franklin, Linus Pauling, and Maurice Wilkins, led to the co-discovery of the double helical structure of DNA. Pauling had previously discovered the secondary structure of proteins using X-ray crystallography. Wilkins and Franklin shared the same laboratory space at King’s College in London, England. There, Franklin was using X-ray diffraction methods to understand the structure of DNA. Watson and Crick, who worked out of the Cavendish laboratory at the University of Cambridge, were able to piece together the puzzle of the DNA molecule based on Franklin’s unpublished photographs (Fig 4.6), which Wilkins had shared (Maddox, 2003). In 1962, James Watson, Francis Crick, and Maurice Wilkins were awarded the Nobel Prize in Medicine. Unfortunately, by then, Franklin had died, and Nobel prizes are not awarded posthumously.

Reading Check #2
Which scientist produced used x-ray crystallography to produce te images that were crucial in leading to the discovery of the structure of DNA?
A. Rosalind Franklin
B. James Watson
C. Francis Crick
D. Maurice Wilkins
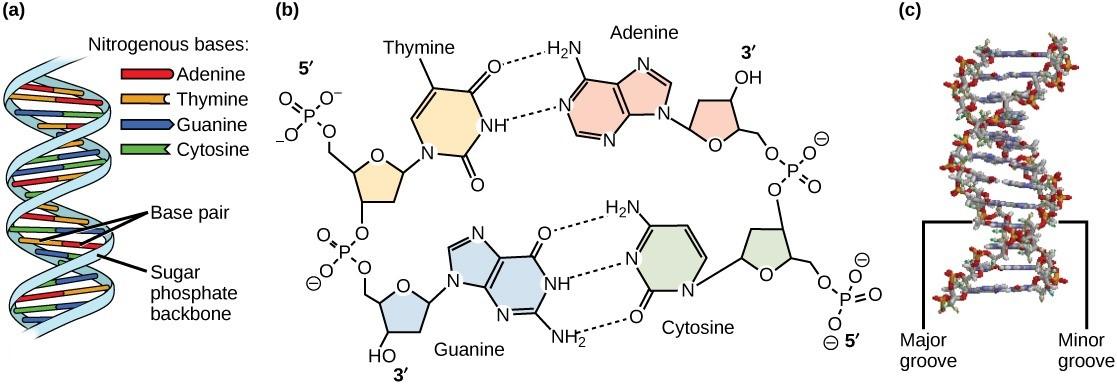
Watson and Crick proposed that DNA is made up of two strands that are twisted around each other to form a double helix. Base pairing takes place between a purine and pyrimidine on opposite strands so that A pairs with T and G pairs with C. Thus, adenine and thymine are complementary base pairs, and cytosine and guanine are also complementary base pairs. The base pairs are stabilized by hydrogen bonds: adenine and thymine form two hydrogen bonds and cytosine and guanine form three hydrogen bonds (Figure 4.7, panel b). The two strands are anti-parallel in nature, meaning the 3′ end of one strand faces the 5′ end of the other strand (Figure 4.7, panel b).
The sugar and phosphate of the nucleotides form the backbone of the structure, whereas the nitrogenous bases are stacked inside, like the rungs of a ladder. The twisting of the two strands around each other results in the formation of uniformly spaced major and minor grooves (Figure 4.7).
Reading Check #3
What is the primary role of hydrogen bonds in DNA?
A. Bonding between adjacent nucleotides
B. Stabilizing the double-stranded structure
C. Forming covalent bonds between atoms
D. Creating a partial positive charge
Reading Check #4
An analysis of a DNA molecule revealed it is composed of 31% thymine nucleotides. What is the percentage of A, G, and C nucleotides?
A. 19% A, 31% G, and 19% C
B. 31% A, 31% G, and 19% C
C. 42% A, 12% G, and 15% C
D. 31% A, 19% G, and 19% C
Reading Check #5
Given the following strand of DNA, what would be the complementary strand? Strand: 5’ AGTTCCGGACAATCTG 3’
A. 5’ UCAAGGCCUGUUAGAC 3’
B. 3’ UCAAGGCCUGUUAGAC 5’
C. 3’ TCAAGGTGTTAGAC 5’
D. 5’ TCAAGGTGTTAGAC 3’
References and Acknowledgments
Maddox, B. (2003). The double helix and the ‘wronged heroine’. Nature 421: 407–408. https://doi.org/10.1038/nature01399
Adapted from Clark, M.A., Douglas, M., and Choi, J. (2018). Biology 2e. OpenStax. Retrieved from https://openstax.org/books/biology-2e/pages/1-introduction

{kind=link}